Run models distilled from DeepSeek-R1 locally!
So, what’s the deal with 深度求索, or DeepSeek as we call it in our part of the world?
DeepSeek is a Chinese company that develops large language models (LLMs). They claim to have developed their models in a shorter time and with far fewer resources than comparable models from OpenAI. This has caused NVIDIA (which produces the hardware used to train and run language models) to take a hit on the stock market, and some even say that DeepSeek has revolutionized the entire AI field.
In recent days, there has been some controversy as OpenAI accuses DeepSeek of using output from ChatGPT to improve its models, which violates ChatGPT’s terms of use.
If you choose to use the online version of DeepSeek, you might want to think twice. The online version has built-in censorship, and what really happens to the data you submit? I don’t know...
Unlike OpenAI’s models, DeepSeek’s models are open-source, so you can run them completely offline on your own hardware—free from censorship and without oversight from Chinese authorities! And best of all: it’s super easy! I’ll show three different ways to do it.
It’s worth noting that ChatGPT is slightly better at the Norwegian language than the destilled DeepSeek models. I have repeatedly experienced responses coming in a strange mix of Bokmål, Nynorsk, Swedish, and Danish—along with occasional phrases in both English and Chinese, especially in the smaller models.
Ollama – From the Command Line
Ollama is a tool that lets you run various types of language models from the command line, available for Windows, Linux, and macOS.
You can download language models from well-known services like 🤗 Hugging Face (where you’ll also find many Norwegian models), or the simplest option is to choose a model from Ollama’s extensive library.
I find DeepSeek R1 and select a “distilled” model of a suitable size. The larger the model, the better the responses, but also the slower it runs. If you have a powerful graphics card (GPU), you should choose a model that fits into the GPU’s VRAM for the best performance.
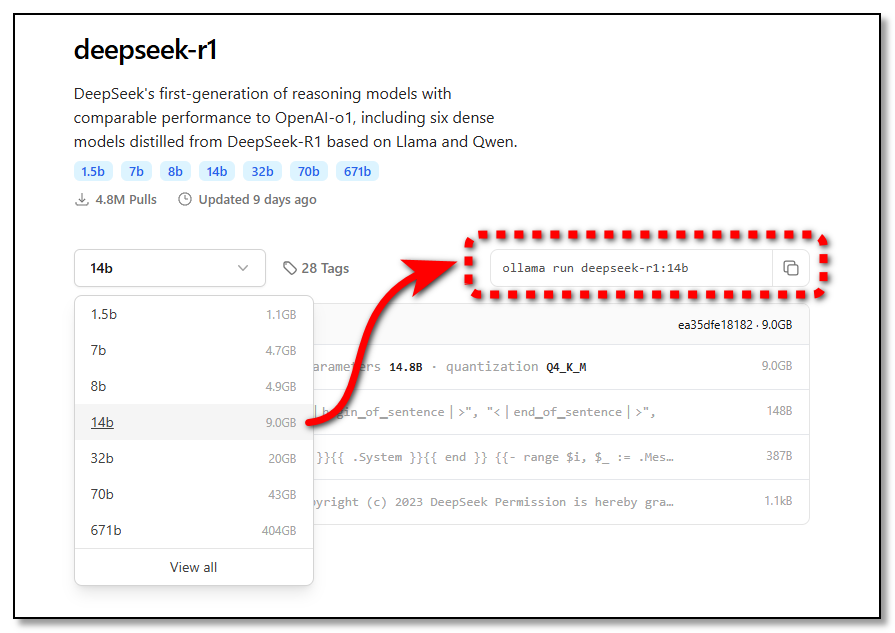
Just copy the Ollama command and run it from the command line. The model downloads the first time you run it and will be ready for use thereafter.
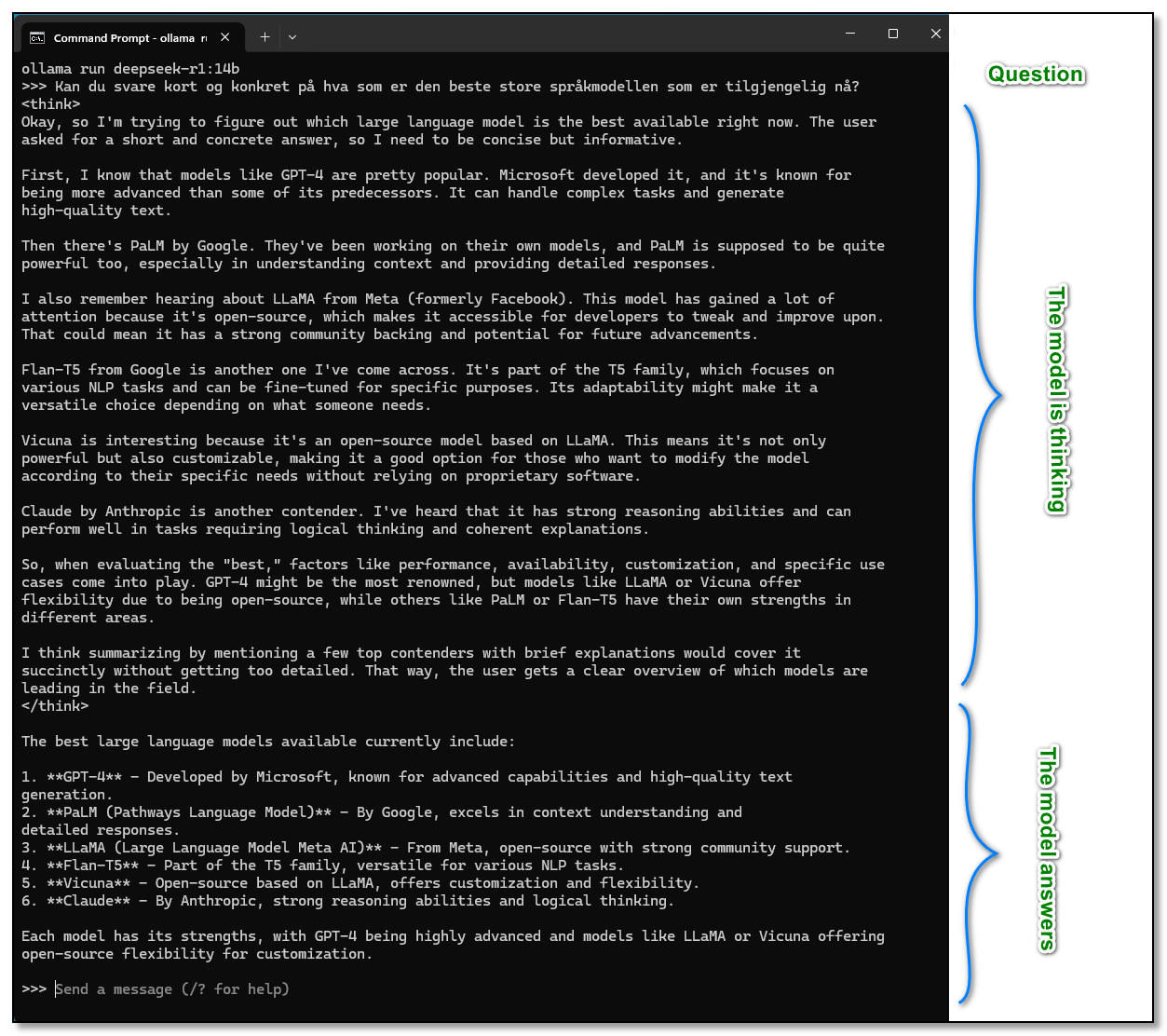
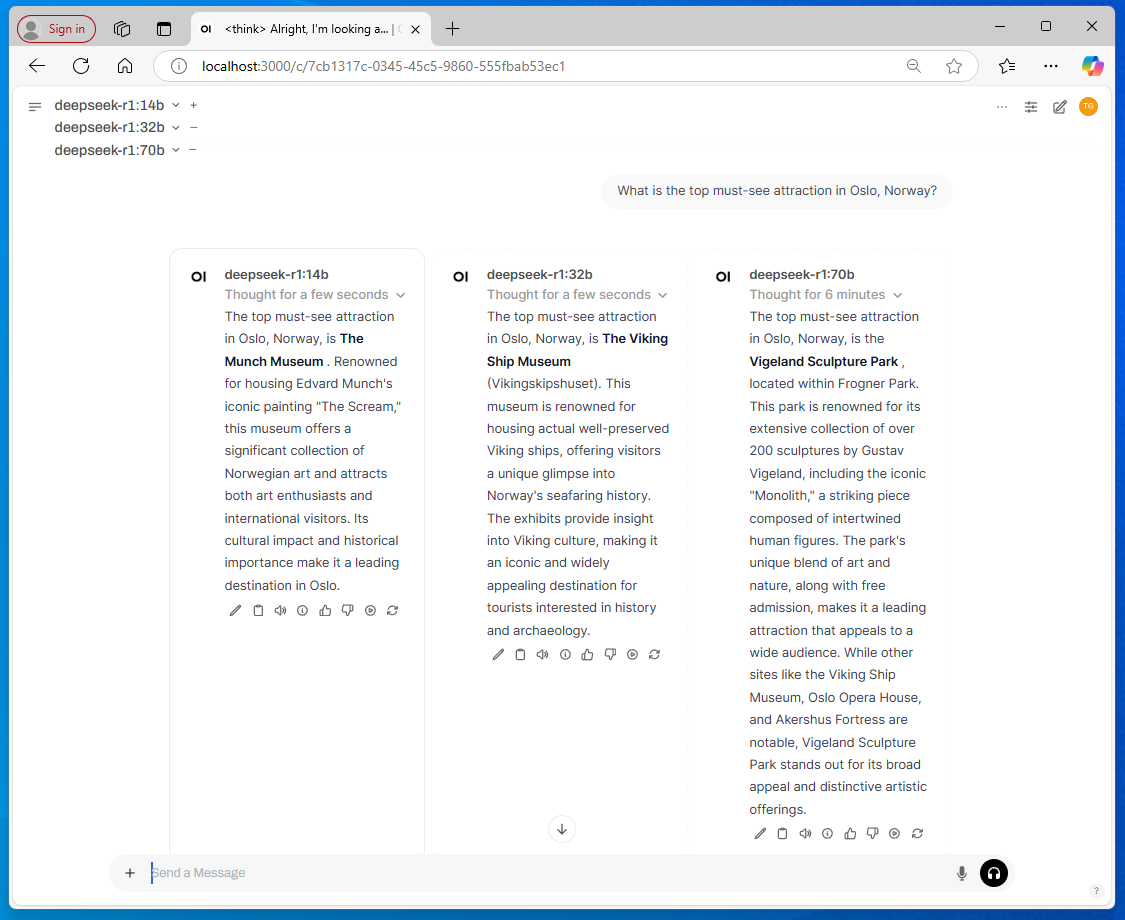
DeepSeek likes to “think carefully” before responding, and as you can see in the screenshot above, most of the returned text consists of its reasoning before it reaches a final answer.
LM Studio – More User-Friendly
There are many ways to run DeepSeek models with a graphical user interface, and LM Studio is one of them. LM Studio is also available for Windows, Linux, and macOS.
Simply install the program and choose the desired model from the library, and you can use the model with a user interface that somewhat resembles ChatGPT.
You can also run a local server to access the language model via an API similar to OpenAI’s APIs.
Open WebUI – Directly in Your Browser
One drawback of LM Studio, as mentioned above, is that if you want to use the same model both from the command line (with Ollama) and from a user interface, you need to download the same model twice.
With Open WebUI, you avoid this, as Open WebUI automatically detects all models installed in Ollama and provides you with a familiar web interface.
Just install Docker Desktop and then run the following command from the command line:
docker run -d -p 3000:8080
--add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data
--name open-webui --restart always ghcr.io/open-webui/open-webui:mainGrab a cup of coffee, and voilà—you can run all your Ollama language models right in your browser!
Here’s an example showing how you can run three variants side by side in Open WebUI – with 14 billion, 32 billion, and 70 billion parameters, respectively – and how they produce different answers to the same question.
Another advantage of running the language model in a browser is that you can use a service like ngrok to make it available over the internet, so you can, for example, use it from your mobile phone.
Enjoy!