Run DeepSeek R1 Locally – With All 671 Billion Parameters
Last week, I showed how to easily run distilled versions of the DeepSeek R1 model locally. A distilled model is a compressed version of a larger language model, where knowledge from a larger model is transferred to a smaller one to reduce resource usage without losing too much performance. These models are based on the Llama and Qwen architectures and come in variants ranging from 1.5 to 70 billion parameters.
Some pointed out that this is not the REAL DeepSeek R1 and that it is impossible to run the full model locally without several hundred GB of memory. That sounded like a challenge – I thought! 😎
First Attempt – Warming up with a 1.58 bit Quantized Version of DeepSeek R1 671b in Ollama.cpp
The developers behind Unsloth dynamically quantized DeepSeek R1 so that it could run on as little as 130GB while still benefiting from all 671 billion parameters.
A quantized LLM is a LLM whose parameters are stored in lower-precision formats (e.g., 8-bit or 4-bit instead of 16-bit). This significantly reduces memory usage and accelerates processing, with minimal impact on performance. The full version of DeepSeek R1 uses 16 bit.
The trade-off in accuracy is hopefully compensated by increased speed.
I downloaded the files from this collection on Hugging Face and ran the following command with Llama.cpp.
llama-cli.exe
--model e:\Huggingface\DeepSeek-R1-UD-IQ1\DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
--cache-type-k q4_0
--threads 16
--prio 2
--temp 0.6
--ctx-size 8192
--seed 3407
--n-gpu-layers 12
-no-cnv
--prompt "<|User|>What is Alan Turing's most important contribution to how we live our lives in 2025?<|Assistant|>"The following table from Unsloth shows the recommended value for the n-gpu-layers parameter, which indicates how much work can be offloaded to the GPU.
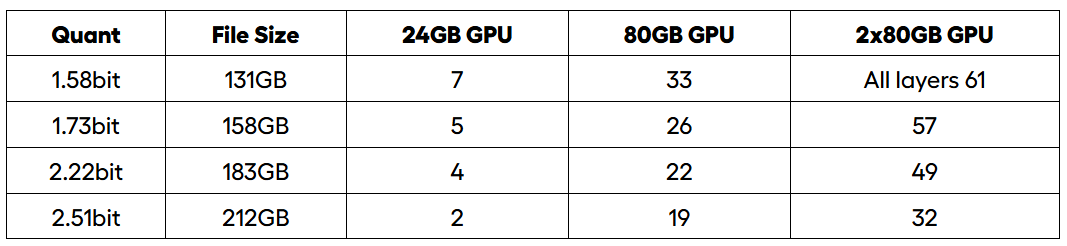
According to the table, I thought 7 should be the maximum, but I got it running with 12. According to Windows Task Manager my GPU has 40 GB of memory, and not 24 as I thought. So then it adds up (7 / 24 * 40 ≈ 12).
If you prefer to run the model directly with Ollama, you must merge the three GGUF files using Llama.cpp or a similar tool first.
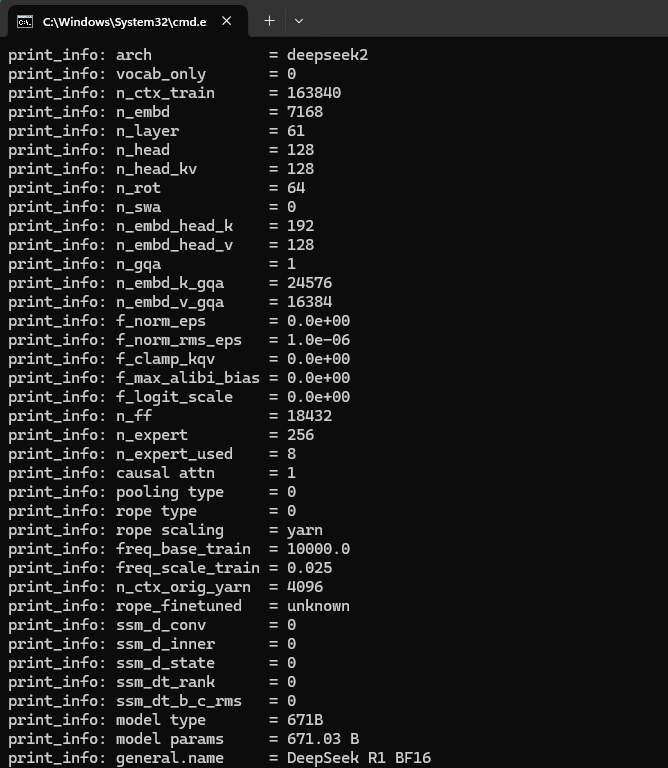
Above is some of the text that appears on screen while running the command.
Llama.cpp and the quantized model are heavy on memory and CPU, but also use the GPU (a little) and continuously read from the disk where the model files are kept.

The model repeats the question and is getting ready to begin reasoning.

The reasoning, or thinking, is quite lengthy – which also contributes to the overall time it takes.
Okay, so I need to figure out Alan Turing's most important contribution to how we live our lives in 2025. Hmm. Let's start by remembering who Alan Turing was. He was a British mathematician and computer scientist, right? He's known for his work in code-breaking during World War II, especially with the Enigma machine. Oh, and he's also considered one of the fathers of theoretical computer science and artificial intelligence.
So, his contributions... Well, the Turing Machine concept is fundamental in computer science. It's a theoretical model of a computer, which laid the groundwork for modern computing. Then there's the Turing Test, which is about determining whether a machine can exhibit intelligent behavior indistinguishable from a human. That's related to AI. Also, his work on morphogenesis, which I think is about biological patterns and growth, like how organisms develop shapes and patterns.
Now, how do these contributions affect life in 2025? Well, we're in a world where AI is becoming more prevalent. So maybe his work on the Turing Test is influencing how AI is developed and integrated into society. If the Turing Test is a benchmark for AI intelligence, then advancements in AI that pass this test might be significant. But wait, the Turing Test is more of a philosophical benchmark. Maybe the actual algorithms or concepts he developed are more foundational.
The Turing Machine model is the basis for the stored-program computer, which is the architecture of modern computers. All our computers today, including smartphones, servers, etc., are based on this concept. So, in 2025, even as technology advances, the fundamental principles he laid down would still be the basis for all computational devices. That's pretty huge. Without that, we wouldn't have the computers that power everything from the internet to AI algorithms.
Additionally, his work on code-breaking during WWII led to advancements in cryptography. Modern encryption methods might have roots in his work, which is essential for secure communication in 2025. Everything from online banking to private messaging relies on encryption, so that's a big contribution.
Another angle is his influence on the development of algorithms. The concept of a universal computing machine allows for the creation of complex algorithms that drive AI, data analysis, machine learning, etc. So, any AI systems in 2025 would stem from his foundational work.
Also, morphogenesis might have influenced fields like biology and genetics. Maybe in 2025, understanding biological patterns helps in areas like genetic engineering or synthetic biology. But I'm not sure how directly that ties into daily life compared to computing.
Putting it all together, the most important contribution might be the Turing Machine and the theory of computation, which underpin all modern computing technology. Without that, the digital age wouldn't exist as we know it. In 2025, even with advancements, the basic framework of computation he provided would still be essential. Alternatively, his work on AI and the Turing Test might be more highlighted in an AI-driven future, but the foundational computing theory seems more fundamental.
Wait, but the Turing Test is more about evaluating AI rather than a contribution to technology itself. The real contribution is the theoretical basis for computing, which enabled all the digital tech we have. So, in 2025, all the smart devices, AI, cloud computing, etc., are all built upon the principles he established. Therefore, his most important contribution is the concept of a universal Turing machine, which is the basis for all modern computers, leading to the digital revolution that defines contemporary life.
And finally the answer.
Alan Turing's most significant contribution to how we live in 2025 is his foundational work in theoretical computer science, particularly the concept of the universal Turing machine. This theoretical model established the principles of modern computation, forming the basis for all digital computers. In 2025, this innovation underpins the entire digital world, enabling technologies like artificial intelligence, cloud computing, smartphones, and the internet. Without Turing's conceptual framework, the development of programmable computers and subsequent technologies that define contemporary life—from AI algorithms to secure communication systems—would not have been possible. His work on cryptography and the Turing Test also contributed to secure communications and AI development, but it is the universal Turing machine that remains the cornerstone of our digital existence.
In summary: The 1.58 bit quantized model generated 0.39 tokens per second. In total, it took about 37 minutes to answer the same question.

I was kind of surprised that I was able to run the model with only 32GB of RAM.
Second Attempt – DeepSeek R1 671b in Ollama
Ok, I get it, a quantized model of only 130GB isn't really the full model. Ollama's model library seem to include a full version of DeepSeek R1. It's 404GB with all 671 billion parameters – that should be real enough, right?
No, not really! The version hosted in Ollamas library is the 4 bit quantized version. See Q4_K_M in the screenshot above? It took me a while!
With Ollama installed on my home PC, I just needed to clear 404GB of disk space and run the following command while grabbing a cup of coffee:
ollama run deepseek-r1:671bOkay, it took more than one coffee before the download was complete.

But finally, the download was done, and the excitement grew ... until this message appeared!
![]()
After a quick visit to an online store selling various types of memory, I concluded that my motherboard wouldn't support such large amounts of RAM anyway. But there must be alternatives?
Windows allows for virtual memory, meaning you can swap disk space for virtual (and rather slow) memory. I figured 450GB of extra virtual memory, in addition to my 32GB of real RAM, should be sufficient.
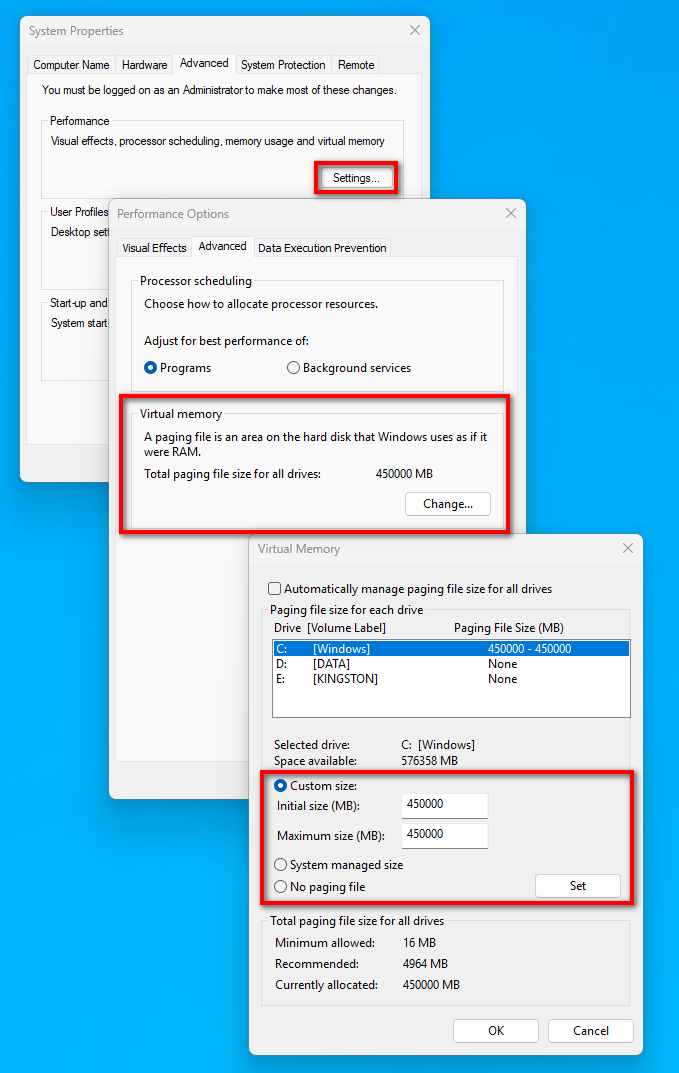
Note: Be aware that SSDs have a limited number of write operations per memory cell before they wear out. Avoid excessive use of virtual memory if this concerns you.
A new attempt, and rising excitement … before another error message!
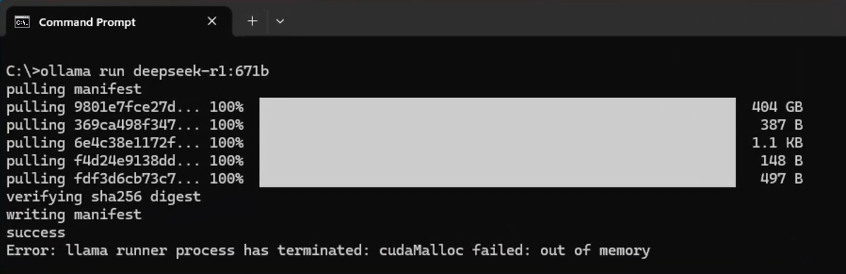
This time, Ollama attempted to push more of the Chinese language model into the GPU's memory than it could handle. After searching online, it seems this is a known issue, but the solution is to let the GPU rest and let the CPU do all the work.
Ollama uses a "Modelfile" containing configuration for the model and how it should be used. When using models directly from Ollama's model library, you usually don't deal with these files as you must when downloading models from Hugging Face or similar sources.
I ran the following command to display the existing configuration for DeepSeek R1:
ollama show --modelfile deepseek-r1:671bThen, I added the following line to the output and saved it in a new file named Modelfile:
PARAMETER num_gpu 0I then created a new model configuration with the following command, where the last parameter is my name for the model, which now runs entirely without GPU usage:
ollama create deepseek-r1-671b-nogpuOnce again, the excitement grew as I nervously typed the following command:
ollama run --verbose deepseek-r1-671b-nogpuSuddenly, it happened! No error message, but tokens started appearing! Admittedly, the speed was such that if you were quick enough, you could almost grab a coffee between each screen update – but it was working! A language model on par with the best from OpenAI, with all its 671 billion parameters, running on my three-year-old PC with 32GB (real) RAM!
I had asked the same question to both ChatGPT (4o, o1, 03-mini-high), DeepSeek R1 hosted in China and DeepSeek R1 671b hosted locally.
What is Alan Turing's most important contribution to how we live our lives in 2025?
This is the reasoning from DeepSeek R1 running in Ollama on my own computer, as it appeared slowly—token by token.
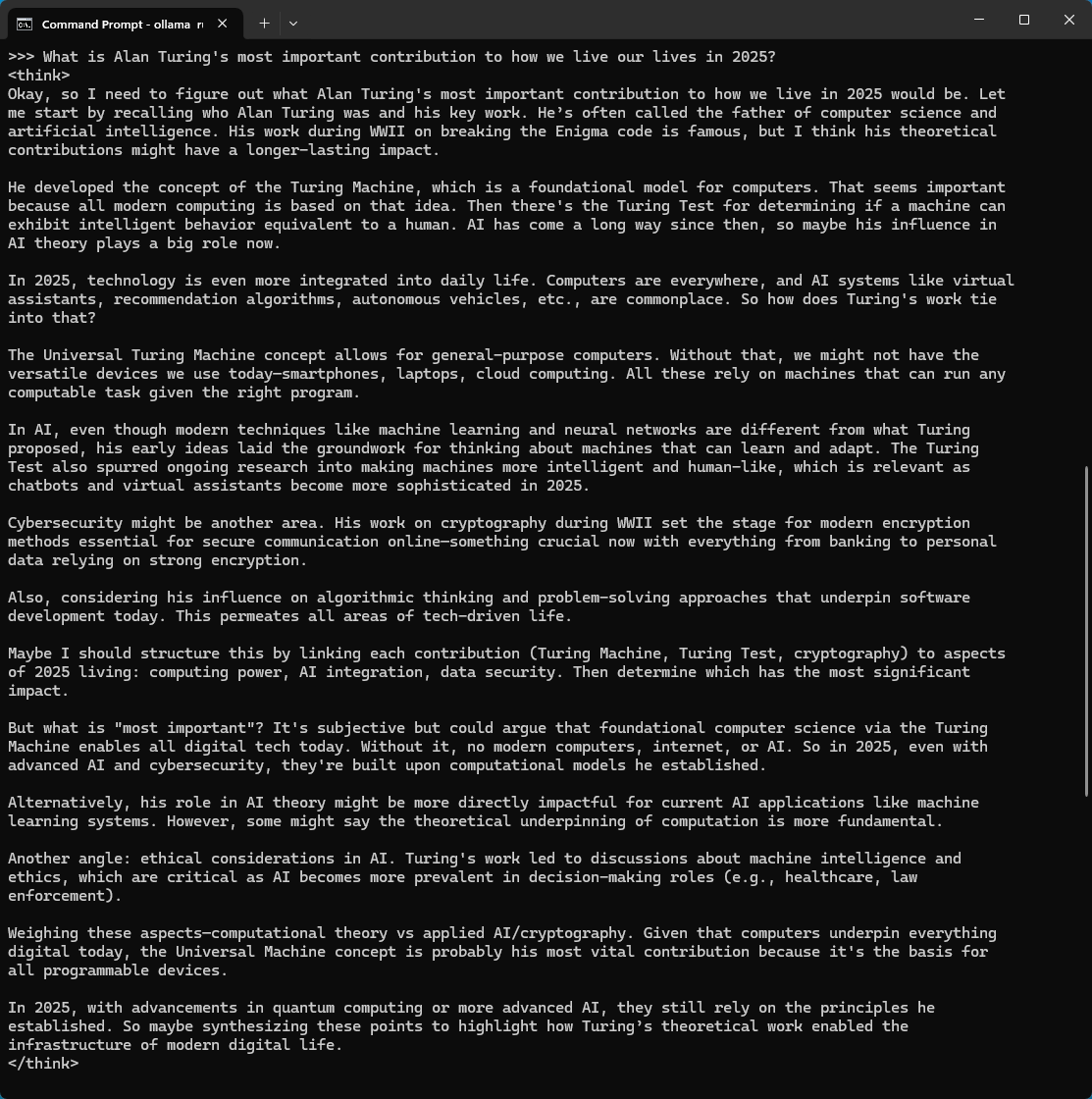
🎉 And finally this is the answer from DeepSeek R1 running in Ollama. The model outputs the answer with markdown formatting.
Alan Turing's most significant contribution to contemporary life, particularly as we look toward 2025, lies in his foundational work on computational theory and artificial intelligence, which underpin nearly every aspect of modern technology. Here’s a structured breakdown:
-
Universal Turing Machine (1936):
- This conceptual model for general-purpose computing is the bedrock of all digital technology today. It established that a single machine could execute any computable task with the right program, enabling:
- Modern Computing Devices (smartphones, cloud infrastructure, IoT).
- Software Development, allowing versatile applications across industries.
- In 2025, advancements in quantum computing, AI, and edge computing still rely on Turing’s principles of programmable logic.
- This conceptual model for general-purpose computing is the bedrock of all digital technology today. It established that a single machine could execute any computable task with the right program, enabling:
-
Artificial Intelligence & the Turing Test (1950):
- His framework for evaluating machine intelligence spurred decades of research into human-like AI. By 2025, this legacy is evident in:
- Advanced chatbots, virtual assistants (e.g., GPT-4/5), and autonomous systems.
- Ethical debates around AI decision-making in healthcare, finance, and law.
- His framework for evaluating machine intelligence spurred decades of research into human-like AI. By 2025, this legacy is evident in:
-
Cryptography & Security:
- Turing’s WWII codebreaking work foreshadowed modern encryption techniques critical for:
- Securing digital transactions, personal data, and blockchain technologies.
- Combating cyber threats in an increasingly connected world.
- Turing’s WWII codebreaking work foreshadowed modern encryption techniques critical for:
Why the Universal Machine Stands Out: While AI and cryptography are transformative, Turing’s theoretical model of computation is the most fundamental. It enabled the creation of programmable systems that drive today’s innovations—from AI algorithms to quantum computing research. Without this foundation, the digital infrastructure of 2025 simply would not exist.
So, how long did it take, using the 4 bit quantized model? Quite a while! At 0.05 tokens per second – meaning 20 seconds per token – it took almost seven hours to get an answer to my question, including 35 minutes to load the model.
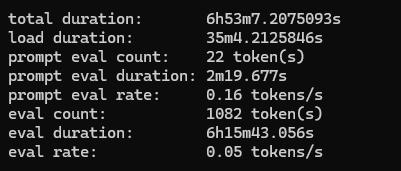
While the model was thinking, the CPU, memory, and the disk (used as virtual memory) were close to 100% busy. The disk where the model file was saved was not busy during generation of the response.
After some reflection, I thought maybe it's okay to wait a bit? Maybe we shouldn't ask language models about everything all the time? Perhaps we should think for ourselves first and be willing to wait for an answer.
This might resemble how computers were used in the 1960s when machines were large and availability was very limited. You prepared your program on a stack of punch cards, which an operator loaded into the machine when it was your turn, and you could (if you were lucky) pick up the result the next day – unless there was an error in your program.
Compared with the response from other LLMs with and without reasoning
DeepSeek R1, hosted in China, thinks for 27 seconds before providing this answer, which is slightly shorter than my locally hosted DeepSeek R1's response.
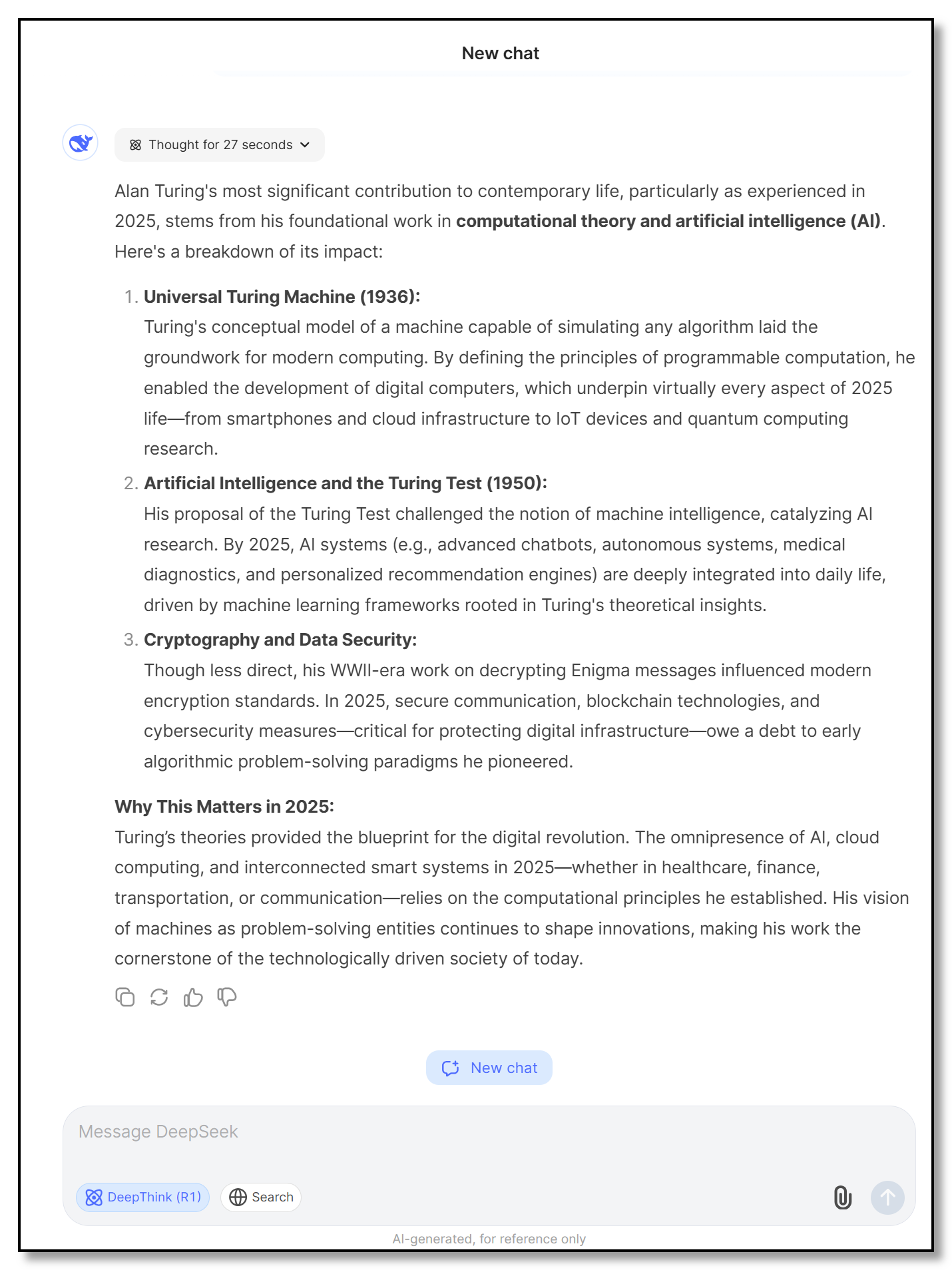
ChatGPT answers similarly to DeepSeek but in a much shorter format, with each model providing slightly different responses. The reasoning models from OpenAI spend less time reasoning than DeepSeek.

That's it – it's definitely possible to run different quantized versions of DeepSeek R1 locally, with all 671 billion parameters – on a three year old computer with 32GB of RAM – just as long as you're not in too much of a hurry!
If you really want the full, non-quantized version of DeepSeek R1 you can find it at Hugging Face. Please let me know your tokens/s (or rather seconds/token) or you get it running!
I think 7 hours per prompt is enough for me, and besides – I'm out of disk space for virtual memory!😄